Kõnetuvastus ehk kõne tekstiks
Rakendus eestikeelsete helisalvestiste automaatseks transkribeerimiseks ning tuvastusvigade korrigeerimiseks.
Kuidas see töötab?
Tekstiks.ee on TTÜ kõnetehnoloogia labori avalik kõnetuvastuse teenus. Süsteem kasutab meie laboris väljatöötatud tehnoloogiat ja mudeleid, mis annavad eesti keele tuvastamisel seni oluliselt parimaid tulemusi kui kommertslikud alternatiivid. Süsteem on täisautomaatne ja samaaegselt võimeline töötlema mitut salvestist. Sellegi poolest võib tööpäevadel esineda suuremat koormust ning pikemat ooteaega. Järjekorra puudumisel kulub kõnetuvastusele ligi pool kõnesalvestise kestusest.
1. Lae kõnesalvestis ülesse
Toetatud on enamlevinud heli- ja videoformaadid. Maksimaalne suurus on 500MB.
2. Oota teksti valmimist
Masinõppe meetoditega treenitud süsteem otsib kõigepealt eestikeelset kõne ning kõnelejate vahetumisi, seejärel transkribeerib kõne tekstiks ning lõpuks lisab kirjavahemärgid. Mitmed tuntud eestlased identifitseerib süsteem ka nimeliselt.
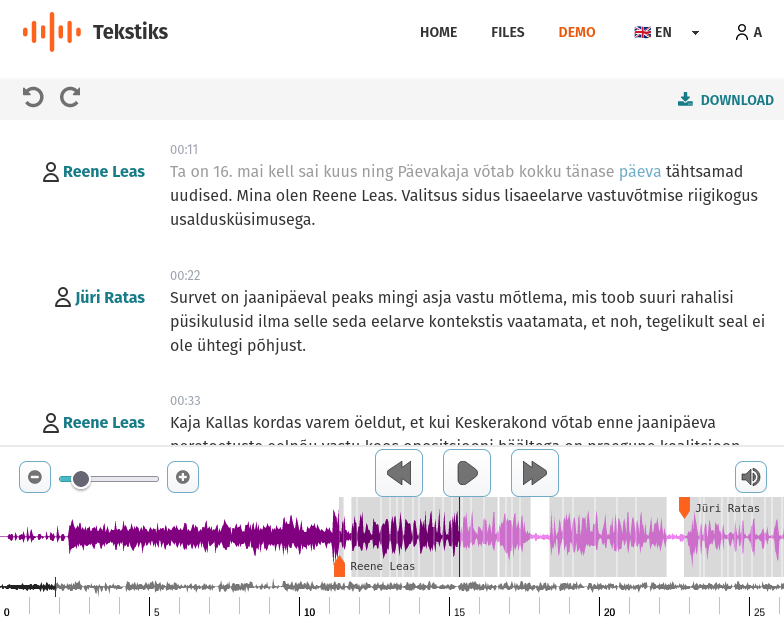
3. Paranda tuvastusvead
Teksti redigeerimine on interaktiivne. Heli mängides värvub hetkel kuuldaolev sõna, mis aitab keerulisemad kohad üle kuulata ja seeläbi teksti käsitsi korrigeerida.
4. Laadi tulemus alla
Toetatud on docx formaat.
Nõuanded
- Helifailis olev kõne peaks olema võimalikult hea kvaliteediga, s.t. lindistatud suu lähedal oleva mikrofoniga müravabas keskkonnas. Helifail peaks olema vähemalt 16-bit kodeeringus ja 16 KHz sagedusega, eelistatult WAV formaadis.
- Kuna maksimaalne üleslaetava faili suurus on 500 MB, siis võib pikemad WAV-failid kodeerida mp3 või ogg vormingusse, aga soovitav on siis kasutada vähemalt 128 kbit kodeeringut. Mahtu aitab kokku hoida ka stereovormingu muutmine monoks (tuvastuse käigus tehakse seda nagunii).
- Süsteem ei tööta hästi kahest tunnist pikemate helifailidega. Selliste failidega võib tuvastus ebaõnnetuda ja tuvastustulemust siis kasutajale ei saadata. Soovitame pikad failid eelnevalt tükeldada.
- NB! Kuna tuvastusserveri ressurss on piiratud, siis palume mitte üles laadida rohkem kui 10 salvestust päevas. Vastasel juhul tekib süsteemis pikk järjekord kõikide kasutajate jaoks. Kui vajate väga paljude failide (näit. terve heliarhiivi) transkribeerimist, siis kontakteeruge meiega.
Viitamine
Kui kasutate seda süsteemi teadustööks, siis palun viidata oma publikatsioonides alltoodud artiklile (saadaval siin): Olev, Aivo; Alumäe, Tanel. "Estonian Speech Recognition and Transcription Editing Service". Baltic J. Modern Computing, Vol. 10 (2022), No. 3, pp. 409–421 https://doi.org/10.22364/bjmc.2022.10.3.14
Vabavara
Tekstiks.ee põhineb vabavaralistel lahendustel, mida on lihtne ise ülesse seada. Tuvastussüsteemi saab kasutada ka Docker konteineri baasil (soovituslik).
- Kõnetuvastuse süsteem. Toimib samm-sammulise protsessina, mille sammude läbimist on võimalik jälgida. Käivitatav käsurealt. https://github.com/taltechnlp/est-asr-pipeline
- Veebiserveri lahendus, mille abil saab luua lihtsa API, mille kaudu kõnetuvastust kasutada. Toetab ka reaalajas töötlemise progressi tagastamist. https://github.com/taltechnlp/est-asr-backend